Parallel Analysis: Determining the Dimensionality of Data
Recently, my colleague asked me to review a state assessment tech report. In the tech report, a section-“Parallel Analysis” really caught my eyes.
I have done parallel analysis multiple times in the past. However, I have never thought about this topic in a systematical way. It is always a good memory refreshing opportunity.
Therefore, I take this tech report reviewing opportunity to dig down the parallel analysis. The first thing I did is searching materials on internet and creating some source code in both SAS and R. Fortunately, there are a lot of information online. After 2 hours searching and reading, I’ve filtered some introductions and materials I thought might be useful for me and you for the possible parallel analysis in the future.
So, before I start sharing materials, let me give you a brief introduction about what is parallel analysis. And how are we going to use it in our analysis.
1 WHAT IS PARALLEL ANALYSIS
When we operate factor analysis, the first decision that we will face in our factor analysis is the decision as to the number of factors that we will need to extract, in order to achieve the most parsimonious (but still interpretatable) factor structure.
There are a number of methods that we could use, but the two most commonly employed methods are the scree plot, and parallel analysis.
So here’s how parallel analysis helps you to decide how may factors to retain. You start with creating a scree plot, in which you plot the eigenvalues (variance explained), in descending order, of each factor you could conceivably extract. The scree plot is so-named because of the scree test proposed by Cattell (1966), who suggested you could look at where the “scree”–a term for rubble at the base of a hill–begins, in order to determine how many factors are necessary to retain.
Sometimes this scree test is a legitimately helpful tool for making factor retention decision, but this is most often in cases when scree plots are painfully obvious as to where there is a huge drop and levelling-off of eigenvalues. And as we shall soon see, there are often cases where the beginning of the “scree” is not so easy to identify in a scree plot. In those cases, the scree test is highly subjective at best, and simply uninformative at worst.
Parallel analysis (introduced by Horn, 1965) is a technique designed to help take some of the subjectivity out of interpreting the scree plot. It is a simulation-based method, and the logic is pretty straightforward:
2 METHODOLOGY
Let N represent the number of observations in the dataset, and p represent the number of variables. In general, parallel analysis is completed as follows:
Calculate the
p x psample correlation matrix from theN x psample dataset. Create a scree plot by plotting the eigenvalues of the sample correlation matrix against their position from largest to smallest (1, 2,…,p) and connecting the points with straight linesGenerate a simulated dataset with N observations randomly sampled from
pindependent normal variates. Calculate thep x pcorrelation matrix for this simulated data and extract the p eigenvalues and order them from largest (position1) to smallest (positionp).Repeat step 2,
ktimes (e.g.,k = 1000).Calculate the median of the of the k eigenvalues at position 1 from steps 2-3, the median of the
klargesteigenvaluesat position2, …, up to the median of thekeigenvalues at positionp.Overlay these medians from step 4 on the scree plot created in step 1, connecting the points.
The intersection of the two lines is the cutoff for determining the number of dimensions present in the data.
Note: other summary statistics can be used in place of the median at step 4 (e.g., 99th percentile, 95th percentile, etc.).
2.1 PARALLEL ANALYSIS IN SAS
In a few minutes, I’ve found a very useful resource online. Kabacoff (2003) published a paper in SAS conference-“Determining the dimensionality of Data: A SAS Macro for Parallel Analysis”. This paper mainly introduce a macro that you can use it to operate parallel analysis.
You can find his paper here
I’ve also reformatted and modified his macro code and it can be download via this link.
3 PARALLEL ANALYSIS IN R
Various R-packages include functions that can conduct parallel analysis. Among all of them, 2 packages are worthwhile to be introduced- paran(Alexis Dinno, 2015), and psych (William Revelle, 2017).
You can find some parallel analysis R code example below.
3.1 paran package example
The key option in the paran function is its centile option.
By default, the centile option is set as \(50%\). However, the traditional centile is usually set as \(95%\) or \(99%\).
library(paran)
# ----- Example 1: package - paran --- #
data("USArrests")
## perform a standard parallel analysis on the US Arrest data
# using 50% percentile.
paran(USArrests, iterations=5000)##
## Using eigendecomposition of correlation matrix.
## Computing: 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
##
##
## Results of Horn's Parallel Analysis for component retention
## 5000 iterations, using the mean estimate
##
## --------------------------------------------------
## Component Adjusted Unadjusted Estimated
## Eigenvalue Eigenvalue Bias
## --------------------------------------------------
## 1 2.158486 2.480241 0.321754
## --------------------------------------------------
##
## Adjusted eigenvalues > 1 indicate dimensions to retain.
## (1 components retained)## a conservative analysis with different result (95% and 99%)
paran(USArrests, iterations=5000, centile=95)##
## Using eigendecomposition of correlation matrix.
## Computing: 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
##
##
## Results of Horn's Parallel Analysis for component retention
## 5000 iterations, using the 95 centile estimate
##
## --------------------------------------------------
## Component Adjusted Unadjusted Estimated
## Eigenvalue Eigenvalue Bias
## --------------------------------------------------
## 1 1.960516 2.480241 0.519724
## --------------------------------------------------
##
## Adjusted eigenvalues > 1 indicate dimensions to retain.
## (1 components retained)3.2 psych package example
The 2nd parallel analysis example is from a factor anlaysis tutorial document by Rachael Smyth and Andrew Johnson.
You can find this document here.
library(psych)
data("bfi")
# Describe data
describe(bfi[1:25])## vars n mean sd median trimmed mad min max range skew kurtosis se
## A1 1 2784 2.41 1.41 2 2.23 1.48 1 6 5 0.83 -0.31 0.03
## A2 2 2773 4.80 1.17 5 4.98 1.48 1 6 5 -1.12 1.05 0.02
## A3 3 2774 4.60 1.30 5 4.79 1.48 1 6 5 -1.00 0.44 0.02
## A4 4 2781 4.70 1.48 5 4.93 1.48 1 6 5 -1.03 0.04 0.03
## A5 5 2784 4.56 1.26 5 4.71 1.48 1 6 5 -0.85 0.16 0.02
## C1 6 2779 4.50 1.24 5 4.64 1.48 1 6 5 -0.85 0.30 0.02
## C2 7 2776 4.37 1.32 5 4.50 1.48 1 6 5 -0.74 -0.14 0.03
## C3 8 2780 4.30 1.29 5 4.42 1.48 1 6 5 -0.69 -0.13 0.02
## C4 9 2774 2.55 1.38 2 2.41 1.48 1 6 5 0.60 -0.62 0.03
## C5 10 2784 3.30 1.63 3 3.25 1.48 1 6 5 0.07 -1.22 0.03
## E1 11 2777 2.97 1.63 3 2.86 1.48 1 6 5 0.37 -1.09 0.03
## E2 12 2784 3.14 1.61 3 3.06 1.48 1 6 5 0.22 -1.15 0.03
## E3 13 2775 4.00 1.35 4 4.07 1.48 1 6 5 -0.47 -0.47 0.03
## E4 14 2791 4.42 1.46 5 4.59 1.48 1 6 5 -0.82 -0.30 0.03
## E5 15 2779 4.42 1.33 5 4.56 1.48 1 6 5 -0.78 -0.09 0.03
## N1 16 2778 2.93 1.57 3 2.82 1.48 1 6 5 0.37 -1.01 0.03
## N2 17 2779 3.51 1.53 4 3.51 1.48 1 6 5 -0.08 -1.05 0.03
## N3 18 2789 3.22 1.60 3 3.16 1.48 1 6 5 0.15 -1.18 0.03
## N4 19 2764 3.19 1.57 3 3.12 1.48 1 6 5 0.20 -1.09 0.03
## N5 20 2771 2.97 1.62 3 2.85 1.48 1 6 5 0.37 -1.06 0.03
## O1 21 2778 4.82 1.13 5 4.96 1.48 1 6 5 -0.90 0.43 0.02
## O2 22 2800 2.71 1.57 2 2.56 1.48 1 6 5 0.59 -0.81 0.03
## O3 23 2772 4.44 1.22 5 4.56 1.48 1 6 5 -0.77 0.30 0.02
## O4 24 2786 4.89 1.22 5 5.10 1.48 1 6 5 -1.22 1.08 0.02
## O5 25 2780 2.49 1.33 2 2.34 1.48 1 6 5 0.74 -0.24 0.03sum(complete.cases(bfi[1:25]))## [1] 2436# Bartlett's Test of Sphericity
# The most liberal test is Bartlett's test of sphericity -
# this evaluates whether or not the variables intercorrelate
# at all, by evaluating the observed correlation matrix against an "identity matrix"
# If this test is not statistically significant, you should not
# employ a factor analysis.
cortest.bartlett(bfi[1:25])## $chisq
## [1] 20163.79
##
## $p.value
## [1] 0
##
## $df
## [1] 300# Bartlett's test was statistically significant, suggesting that
# the observed correlation matrix among the items is
# not an identity matrix.
# --- Determining the Number of Factors to Extract --- #
# Test 1: Scree Plot
bfi[,1:25] %>% scree()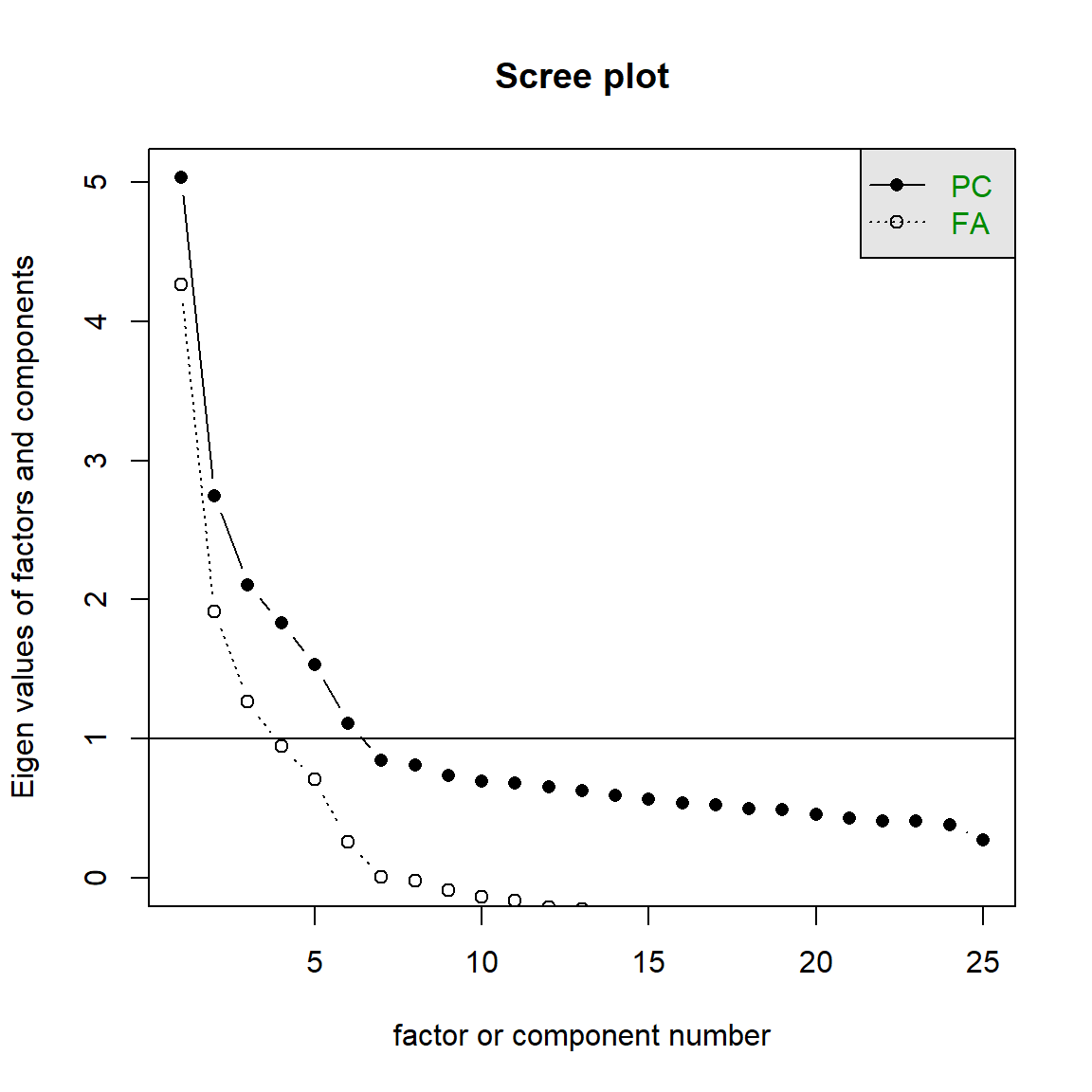
# Test 2: Parallel Analysis
bfi[,1:25] %>% fa.parallel()## Parallel analysis suggests that the number of factors = 6 and the number of components = 6
I also found that a web post by Sakaluk & Short (2016) provides a very good R code example using psych and ggplot to do the parallel analysis.
(Sakaluk, J. K., & Short, S. D. (2016). A Methodological Review of Exploratory Factor Analysis in Sexuality Research: Used Practices, Best Practices, and Data Analysis Resources. Journal of Sex Research.)
You can find the web post here.
library(psych)
library(ggplot2)
# STEP 1: Read-in data
dat <- msq
keys <- make.keys(msq[1:75], list(
EA = c(
"active", "energetic", "vigorous", "wakeful", "wide.awake", "full.of.pep",
"lively", "-sleepy", "-tired", "-drowsy"
),
TA = c(
"intense", "jittery", "fearful", "tense", "clutched.up", "-quiet", "-still",
"-placid", "-calm", "-at.rest"
),
PA = c(
"active", "excited", "strong", "inspired", "determined", "attentive",
"interested", "enthusiastic", "proud", "alert"
),
NAf = c(
"jittery", "nervous", "scared", "afraid", "guilty", "ashamed", "distressed",
"upset", "hostile", "irritable"
),
HAct = c("active", "aroused", "surprised", "intense", "astonished"),
aPA = c("elated", "excited", "enthusiastic", "lively"),
uNA = c("calm", "serene", "relaxed", "at.rest", "content", "at.ease"),
pa = c("happy", "warmhearted", "pleased", "cheerful", "delighted"),
LAct = c("quiet", "inactive", "idle", "still", "tranquil"),
uPA = c("dull", "bored", "sluggish", "tired", "drowsy"),
naf = c("sad", "blue", "unhappy", "gloomy", "grouchy"),
aNA = c("jittery", "anxious", "nervous", "fearful", "distressed"),
Fear = c("afraid", "scared", "nervous", "jittery"),
Hostility = c("angry", "hostile", "irritable", "scornful"),
Guilt = c("guilty", "ashamed"),
Sadness = c("sad", "blue", "lonely", "alone"),
Joviality = c("happy", "delighted", "cheerful", "excited", "enthusiastic", "lively", "energetic"), Self.Assurance = c("proud", "strong", "confident", "-fearful"),
Attentiveness = c("alert", "determined", "attentive")
# acquiscence = c('sleepy' , 'wakeful' , 'relaxed','tense')
))
# obtain efa data
msq.scores = scoreItems(keys,msq[1:75])
efa.data = msq.scores$scores
set.seed(123)
parallel = fa.parallel(efa.data, # specify our data frame;
fm = 'ml', # indicate that we want to estimate eigenvalues using maximum likelihood
fa = 'fa', # indicate that we only want the CF eigenvalues
n.iter = 50, # indicate that 50 times simulation for our parallel analysis;
SMC = TRUE, # indicate that we want to use squared multiple correlations (SMCs)
quant = .95) # specify that we would like the 95th quantile## Parallel analysis suggests that the number of factors = 16 and the number of components = NA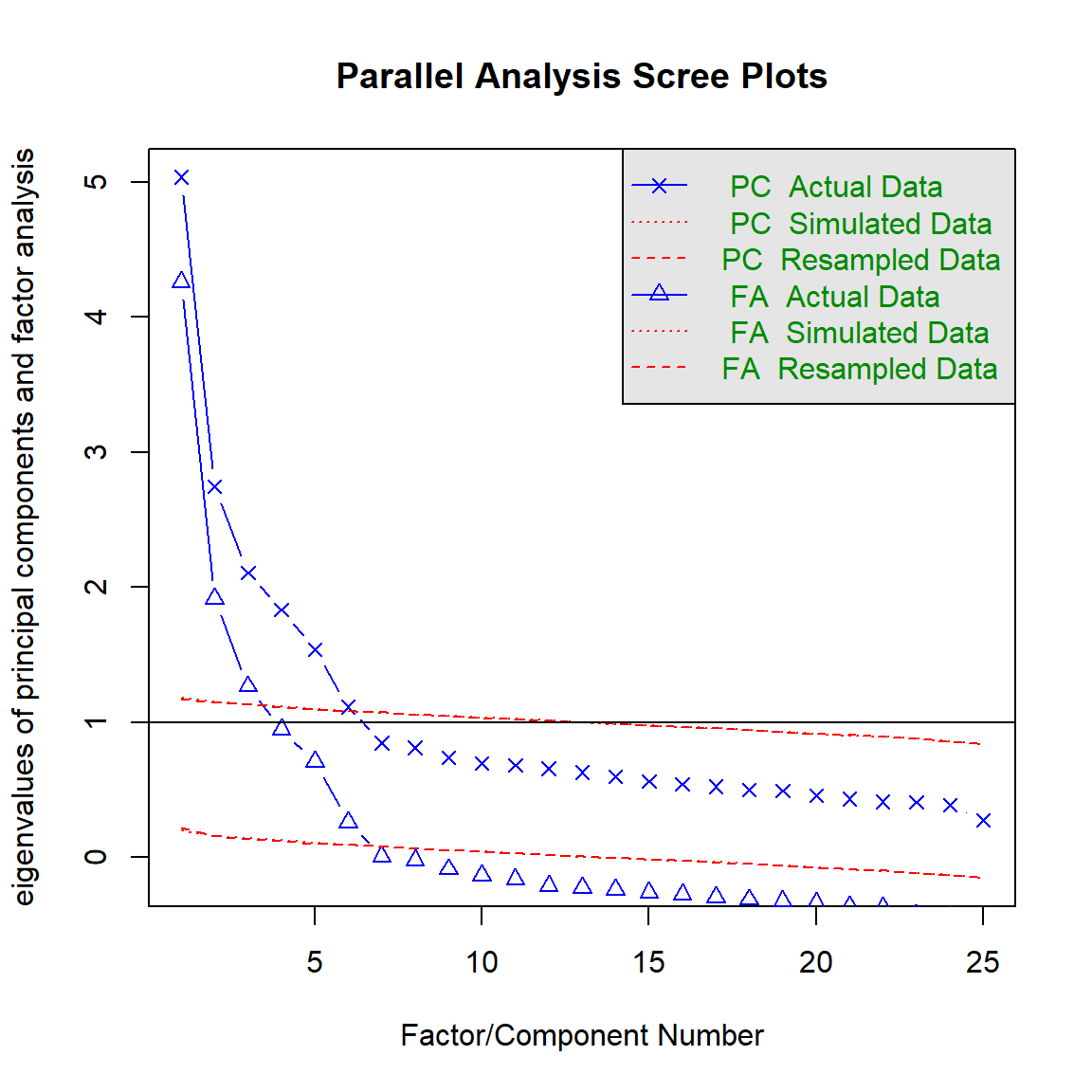
# --- Making a Pretty Scree Plot with Parallel Analysis Using ggplot2 --- #
# STEP 1: Create data frame from observed eigenvalue data
obs <- data.frame(parallel$fa.values)
obs$type <- c('Observed Data')
obs$num <- c(row.names(obs))
obs$num <- as.numeric(obs$num)
colnames(obs) <- c('eigenvalue', 'type', 'num')
# STEP 2: Calculate quantiles for eigenvalues,
# but only store those from simulated CF model in percentile1
percentile <- apply(parallel$values, 2, function(x) quantile(x, .95))
min <- as.numeric(nrow(obs))
min <- (4 * min) - (min - 1)
max <- as.numeric(nrow(obs))
max <- 4 * max
percentile1 <- percentile[min:max]
# Create data frame called &amp;amp;amp;amp;quot;sim&amp;amp;amp;amp;quot; with simulated eigenvalue data
sim <- data.frame(percentile1)
sim$type <- c("Simulated Data (95th %ile)")
sim$num <- c(row.names(obs))
sim$num <- as.numeric(sim$num)
colnames(sim) <- c("eigenvalue", "type", "num")
# Merge the two data frames (obs and sim) together into data frame called eigendat
eigendat <- rbind(obs, sim)
# Apply ggplot2
apatheme <- theme_bw() +
theme(
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
panel.border = element_blank(),
text = element_text(family = "Arial"),
legend.title = element_blank(),
legend.position = c(.7, .8),
axis.line.x = element_line(color = "black"),
axis.line.y = element_line(color = "black")
)
# Use data from eigendat. Map number of factors to x-axis, eigenvalue to y-axis, and give different data point shapes depending on whether eigenvalue is observed or simulated
p <- ggplot(eigendat, aes(x = num, y = eigenvalue, shape = type)) +
# Add lines connecting data points
geom_line() +
# Add the data points.
geom_point(size = 4) +
# Label the y-axis 'Eigenvalue'
scale_y_continuous(name = "Eigenvalue") +
# Label the x-axis 'Factor Number', and ensure that it ranges from 1-max # of factors, increasing by one with each 'tick' mark.
scale_x_continuous(name = "Factor Number", breaks = min(eigendat$num):max(eigendat$num)) +
# Manually specify the different shapes to use for actual and simulated data, in this case, white and black circles.
scale_shape_manual(values = c(16, 1)) +
# Add vertical line indicating parallel analysis suggested max # of factors to retain
geom_vline(xintercept = parallel$nfact, linetype = "dashed") +
# Apply our apa-formatting theme
apatheme
# Call the plot. Looks pretty!
p## Warning in grid.Call(C_stringMetric, as.graphicsAnnot(x$label)): font family not
## found in Windows font database
## Warning in grid.Call(C_stringMetric, as.graphicsAnnot(x$label)): font family not
## found in Windows font database## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database
## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database## Warning in grid.Call.graphics(C_text, as.graphicsAnnot(x$label), x$x, x$y, :
## font family not found in Windows font database## Warning in grid.Call(C_textBounds, as.graphicsAnnot(x$label), x$x, x$y, : font
## family not found in Windows font database# Save a high-res version of your plot,
# and you've got yourself a pretty scree plot with parallel analysis:
# ggsave('parallel.png', width=6, height=6, unit='in', dpi=300)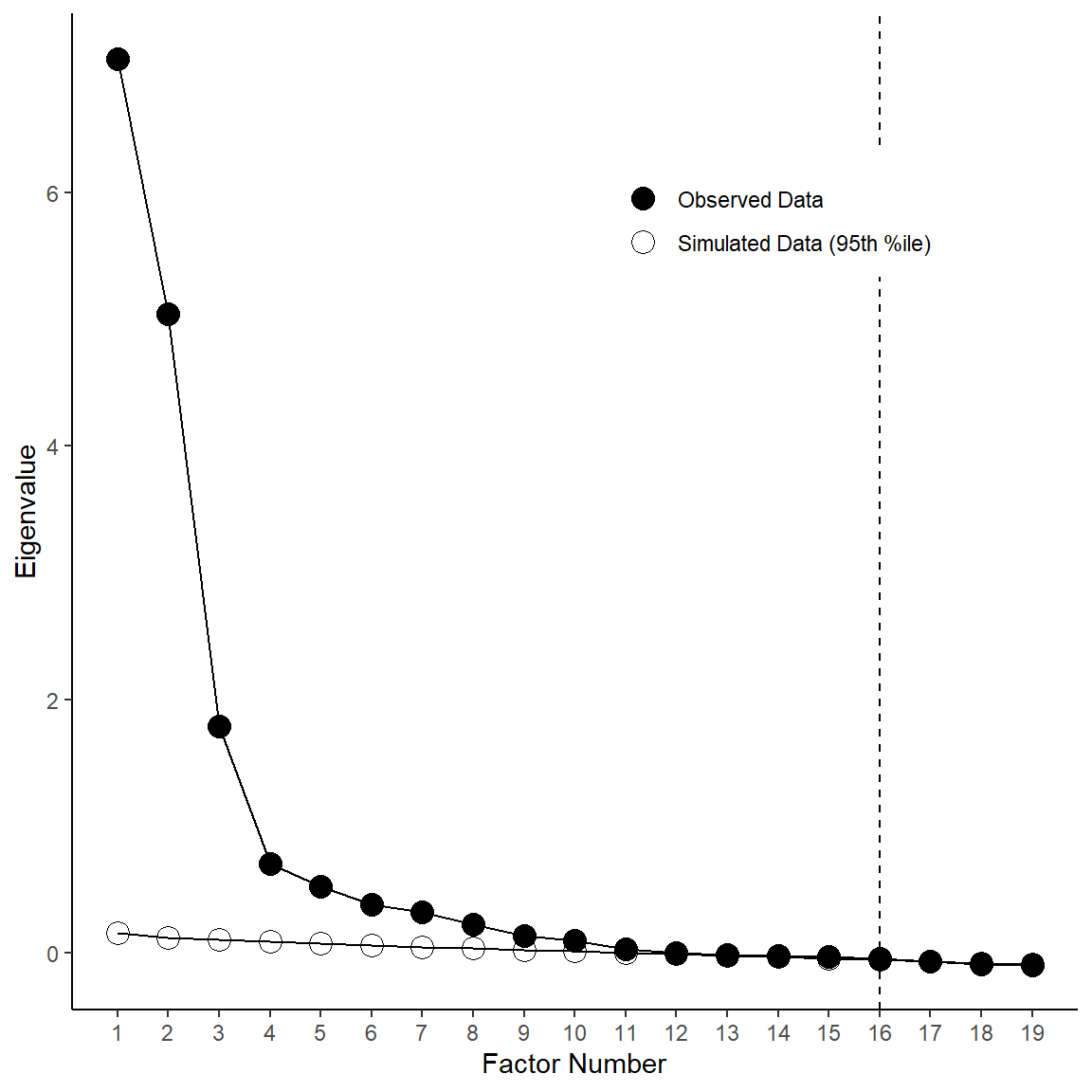
Finally, William Revelle’s psych package tutorial document is helpful too.
You can find her paper here.
Ou Zhang
Research Scientist & Data Scientist
I’m a research scientist, psychometrician, and data scientist, who loves psychometrics, applied statistics, general data science, and programming.